Hiểu mô hình đối tượng tài liệu (DOM) trong chi tiết
Chúng ta đều đã nghe nói về DOM, hoặc là Mô hình Đối tượng Tài liệu, thỉnh thoảng được đề cập đến, liên quan đến JavaScript. DOM là một khái niệm khá quan trọng trong phát triển web. Không có nó, chúng tôi sẽ không thể tự động sửa đổi các trang HTML trong trình duyệt.
Học và hiểu kết quả DOM theo những cách tốt hơn truy cập, thay đổi và giám sát các yếu tố khác nhau của một trang HTML. Mô hình đối tượng tài liệu cũng có thể giúp chúng ta giảm sự gia tăng không cần thiết trong thời gian thực hiện tập lệnh.
Cây cấu trúc dữ liệu
Trước khi nói về DOM là gì, nó tồn tại như thế nào, nó tồn tại như thế nào và những gì xảy ra bên trong nó, tôi muốn bạn biết về cây. Không phải loại cây lá kim & rụng lá mà là về cây cấu trúc dữ liệu.
Việc hiểu khái niệm cấu trúc dữ liệu sẽ dễ dàng hơn rất nhiều nếu chúng ta đơn giản hóa định nghĩa của nó. Tôi có thể nói, một cấu trúc dữ liệu là về sắp xếp dữ liệu của bạn. Vâng, chỉ đơn giản là sắp xếp cũ, vì bạn sẽ sắp xếp đồ đạc trong nhà hoặc sách trong giá sách hoặc tất cả các nhóm thực phẩm khác nhau mà bạn đang dùng cho một bữa ăn trên đĩa của bạn để làm cho nó có ý nghĩa với bạn.
Tất nhiên, đó không phải là tất cả về cấu trúc dữ liệu, nhưng đó là nơi tất cả bắt đầu. Điều này “sắp xếp” là trung tâm của tất cả Nó cũng khá quan trọng trong DOM. Nhưng chúng tôi chưa nói về DOM, vì vậy hãy để tôi hướng bạn đến cấu trúc dữ liệu mà bạn có thể quen thuộc: mảng.
Mảng & cây xanh
Mảng có chỉ số và chiều dài, họ có thể đa chiều, và có nhiều đặc điểm hơn. Điều quan trọng không kém là phải biết những điều này về mảng, chúng ta đừng bận tâm đến điều đó ngay bây giờ. Đối với chúng tôi, một mảng là khá đơn giản. Đó là khi bạn sắp xếp những thứ khác nhau trong một dòng.

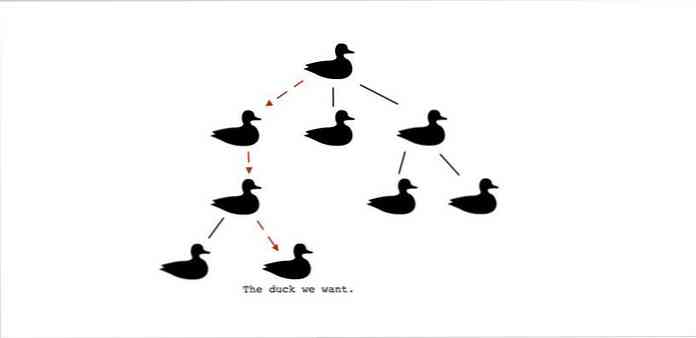
Tương tự như vậy, khi nghĩ về cây, hãy nói, đó là về đặt những thứ bên dưới nhau, bắt đầu chỉ với một thứ ở trên cùng.
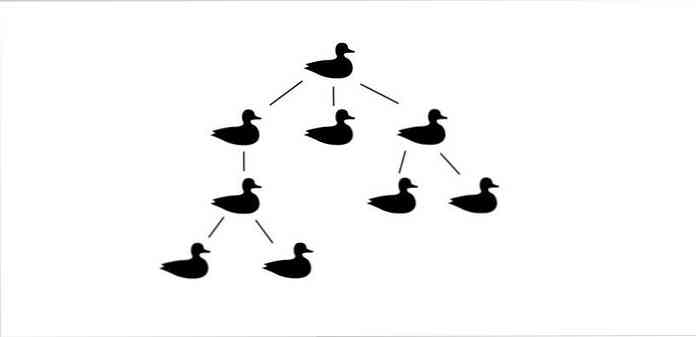
Bây giờ, bạn có thể lấy một dòng vịt từ trước, bật nó lên, và nói với tôi rằng “Bây giờ, mỗi con vịt ở dưới một con vịt khác”. Có phải là cây không? Nó là.
Tùy thuộc vào dữ liệu của bạn là gì hoặc bạn sẽ sử dụng dữ liệu đó như thế nào, dữ liệu trên cùng trong cây của bạn (được gọi là nguồn gốc) có thể là một cái gì đó là có tầm quan trọng rất lớn hoặc một cái gì đó chỉ có ở đó để kèm theo các yếu tố khác bên dưới nó.
Dù bằng cách nào, phần tử trên cùng trong cấu trúc dữ liệu cây làm một việc rất quan trọng. Nó cung cấp một nơi để bắt đầu tìm kiếm bất kỳ thông tin nào chúng tôi muốn trích xuất từ cây.
Ý nghĩa của DOM
DOM là viết tắt của Mô hình Đối tượng Tài liệu. Tài liệu trỏ đến một tài liệu HTML (XML) đó là đại diện như một đối tượng. (Trong JavaScript, mọi thứ chỉ có thể được biểu diễn dưới dạng một đối tượng!)
Mô hình là được tạo bởi trình duyệt lấy một tài liệu HTML và tạo một đối tượng đại diện cho nó. Chúng ta có thể truy cập đối tượng này bằng JavaScript. Và vì chúng tôi sử dụng đối tượng này để thao tác với tài liệu HTML và xây dựng các ứng dụng của riêng mình, DOM về cơ bản là một API.
Cây DOM
Trong mã JavaScript, tài liệu HTML là đại diện như một đối tượng. Tất cả dữ liệu đọc từ tài liệu đó là cũng được lưu dưới dạng đối tượng, lồng nhau (vì như tôi đã nói trước đây, trong JavaScript, mọi thứ chỉ có thể được biểu diễn dưới dạng đối tượng).
Vì vậy, về cơ bản, đây là sự sắp xếp vật lý của dữ liệu DOM trong mã: mọi thứ đều sắp xếp như đồ vật. Theo logic, tuy nhiên, nó là một cái cây.
Trình phân tích cú pháp DOM
Mỗi phần mềm trình duyệt có một chương trình được gọi là Trình phân tích cú pháp DOM đó là trách nhiệm cho phân tích tài liệu HTML vào DOM.
Các trình duyệt đọc một trang HTML và biến dữ liệu của nó thành các đối tượng tạo nên DOM. Thông tin có trong các đối tượng DOM JavaScript này được sắp xếp một cách hợp lý dưới dạng cây cấu trúc dữ liệu được gọi là cây DOM.
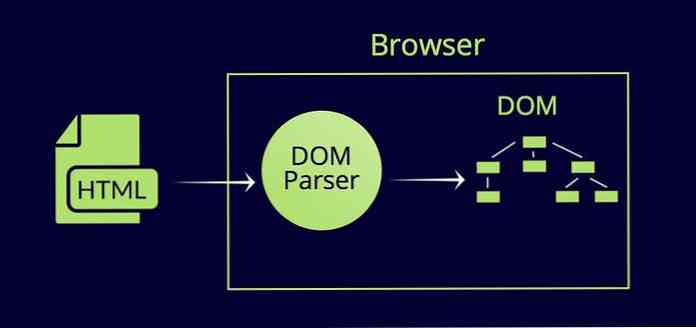
Phân tích dữ liệu từ HTML sang cây DOM
Lấy một tệp HTML đơn giản. Nó có yếu tố gốc . Nó là yếu tố phụ là và , mỗi cái có nhiều yếu tố con.
Về cơ bản, trình duyệt đọc dữ liệu trong tài liệu HTML, một cái gì đó tương tự như thế này:
Và, sắp xếp chúng thành một cây DOM như thế này:
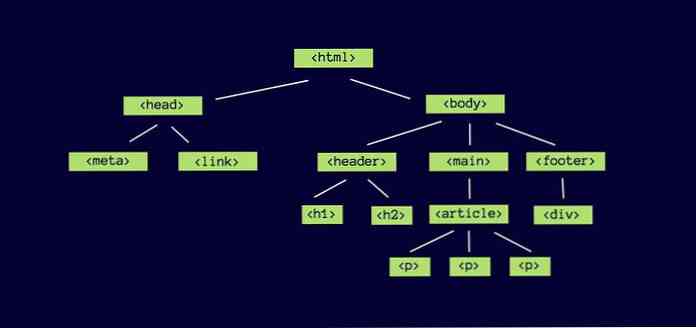
Sự biểu diễn của từng thành phần HTML (và nội dung thuộc về nó) trong cây DOM được gọi là Nút. Các Nút gốc là nút của .
Các Giao diện DOM trong JavaScript được gọi là tài liệu (vì đó là đại diện của tài liệu HTML). Do đó, chúng tôi truy cập vào cây DOM của tài liệu HTML thông qua tài liệu giao diện trong JavaScript.
Chúng tôi không thể chỉ truy cập, mà còn thao tác với tài liệu HTML thông qua DOM. Chúng tôi có thể thêm các yếu tố vào một trang web, xóa và cập nhật chúng. Mỗi lần chúng tôi thay đổi hoặc cập nhật bất kỳ nút nào trong cây DOM, nó sẽ phản ánh trên trang web.
Các nút được thiết kế như thế nào
Tôi đã đề cập trước đó rằng mọi phần dữ liệu từ tài liệu HTML là được lưu dưới dạng một đối tượng trong JavaScript. Vì vậy, làm thế nào dữ liệu được lưu dưới dạng đối tượng có thể được sắp xếp một cách hợp lý dưới dạng cây?
Các nút của cây DOM có các đặc tính hoặc thuộc tính nhất định. Hầu như mọi nút trong cây có một nút cha (nút ngay bên trên nó), hạch con (các nút bên dưới nó) và anh chị em ruột (các nút khác thuộc cùng cha mẹ). Có cái này gia đình bên trên, bên dưới và xung quanh một nút là những gì đủ điều kiện là một một phần của cây.
Thông tin gia đình này của mỗi nút là lưu dưới dạng các thuộc tính trong đối tượng đại diện cho nút đó. Ví dụ, bọn trẻ là một thuộc tính của một nút mang danh sách các phần tử con của nút đó, do đó sắp xếp một cách hợp lý các phần tử con của nó dưới nút đó.
Tránh lạm dụng thao tác DOM
Nhiều như chúng ta có thể thấy việc cập nhật DOM hữu ích (để sửa đổi trang web), có một điều như làm quá.
Nói rằng, bạn muốn cập nhật màu của Nhưng, nếu bạn muốn loại bỏ một nút từ cây hoặc là thêm một vào nó? Toàn cây có thể phải được sắp xếp lại, với nút bị loại bỏ hoặc thêm vào cây. Đây là một công việc tốn kém. Phải mất thời gian và tài nguyên trình duyệt để hoàn thành công việc này. Ví dụ: giả sử bạn muốn thêm năm hàng vào bảng. Đối với mỗi hàng, khi các nút mới của nó được tạo và thêm vào DOM, cây được cập nhật mỗi lần, tổng cộng tối đa năm bản cập nhật. Chúng ta có thể tránh điều này bằng cách sử dụng Điều này không chỉ xảy ra khi chúng ta loại bỏ hoặc thêm các yếu tố, nhưng thay đổi kích thước một phần tử cũng có thể ảnh hưởng đến các nút khác, vì phần tử đã thay đổi kích thước có thể cần các phần tử khác xung quanh nó để điều chỉnh kích thước của chúng. Vì vậy, các nút tương ứng của tất cả các yếu tố khác sẽ cần được cập nhật và các yếu tố HTML sẽ được hiển thị lại theo quy tắc mới. Tương tự như vậy, khi toàn bộ bố cục của một trang web bị ảnh hưởng, một phần hoặc toàn bộ trang web có thể được kết xuất lại. Đây là quá trình được gọi là Từ chối. Để mà tránh trào ngược quá mức đảm bảo bạn không thay đổi DOM quá nhiều. Các thay đổi đối với DOM không phải là điều duy nhất có thể gây ra Reflow trên trang web. Tùy thuộc vào trình duyệt, các yếu tố khác cũng có thể đóng góp cho nó. Kết thúc mọi thứ, DOM là hình dung như một cái cây bao gồm tất cả các yếu tố được tìm thấy trong một tài liệu HTML. Về mặt vật lý (vật lý như mọi thứ kỹ thuật số có thể có), đó là một tập hợp các đối tượng JavaScript lồng nhau trong đó các thuộc tính và phương thức chứa thông tin làm cho nó có thể hợp lý sắp xếp chúng thành một cái cây.Tài liệuFragment giao diện. Hãy nghĩ về nó như một cái hộp có thể giữ tất cả năm hàng và được thêm vào cây. Bằng cách này, năm hàng là được thêm vào dưới dạng một mẩu dữ liệu và không phải từng cái một, dẫn đến chỉ một bản cập nhật trong cây.Gói lại